Characteristics of Open Data

Definitions
Open(ness)
The term Open(ness) can be defined in the following complementary ways:
- General Definition:
Open means anyone can freely access, use, modify, and share for any purpose (subject, at most, to requirements that preserve provenance and openness).
The Open Definition according to the Open Knowledge Network.
- Principles of Openness:
- No limitations on access: Accessibility must not depend on cost, authentication, or privileges (national, institutional, or otherwise).
- Free and open: Open knowledge should be shared freely, without cost or barriers.
Derived from the Open Knowledge Foundation’s principles and scholarly interpretations.
→ Key takeaway: Knowledge funded by public mandates must benefit the public without restrictions Scholger (2023).
Data
Data at its most basic level as the absence of uniformity, whether in the real world or in some symbolic system. Only once such data have some recognisable structure and are given some meaning can they be considered information (Floridi, 2010).

Metadata
Data whose purpose is to describe and give information about other data. (Oxford English Dictionary, 2023b)
(…) there is no fixed boundary between “data” and “metadata”, and that information viewed as data in one discipline may be metadata in another. (Alter et al., 2023)
Open Data
Open data and content can be freely used, modified, and shared by anyone for any purpose.
The Open Definition according to the Open Knowledge Network.
History
Robert K. Merton (1910–2003)
American sociologist, considered a founding father of modern sociology, said in 1942:
Each researcher must contribute to the ‘common pot’ and give up intellectual property rights to allow knowledge to move forward.
Source: Wikipedia
While the term “open data” isn’t even 20 years old, the author puts the concept in a historical context; the idea that scientific research should be free to all was popularized by Robert King Merton in the early 1940s. Research (which produces data) should be shared freely for the common good.
Timeline
- 1942: The concept starts with Robert K. Merton.
- 1995: The term ‘Open Data’ first appeared, related to the sharing of geophysical and environmental data.
- November 2005: Open Knowledge Foundation creates the Open Definition.
- December 2007: The concept of open public data was discussed and defined in Sebastopol, CA, USA at a meeting of Internet activists. They identified 8 principles.
- February 2009: Tim Berners-Lee presents The Next Web at TED2009. He famously asked for “raw data now”.
https://devopedia.org/open-data
https://www.opendatasoft.com/en/what-is-open-data-practical-guide/
The Sebastopol Meeting
In December 2007, thirty thinkers and activists of the Internet held a meeting in Sebastopol, north of San Francisco. Their aim was to define the concept of open public data and have it adopted by the US presidential candidates.
Among them were:
- Tim O’Reilly: An American author and editor who defined and popularized concepts such as open source and Web 2.0.
- Lawrence Lessig: Professor of Law at Stanford University and founder of Creative Commons licenses.
- Adrian Holovaty: Founder of EveryBlock, a localized information service.
- Tom Steinberg: Founder of the FixMyStreet site.
- Aaron Swartz: Inventor of RSS and free knowledge activist.
Together, they created principles to define and evaluate open public data.
https://www.paristechreview.com/2013/03/29/brief-history-open-data/
The Impact of Open Data on Disciplines
Catalysing Interdisciplinary Progress
- A foundation for collaboration and innovation: Open data drives interdisciplinary research by providing universally accessible datasets, fostering collaboration across diverse fields such as information science, digital humanities, and data science.
- Enabling data-driven research: Facilitates advanced analysis and research in disciplines that rely heavily on data, increasing the accuracy and depth of insights and discoveries.
Open Data in Information Science, Digital Humanities, and Data Science
- Information Science: Improves data management and accessibility, enabling more efficient data retrieval, archiving, and dissemination practices.
- Digital Humanities: Enables new digital approaches to humanities research, providing new insights into historical, cultural, and linguistic studies through data analysis.
- Data Science: Leverages open data for predictive modeling, machine learning, and big data analytics, enabling comprehensive analysis and informed decision-making in diverse fields such as health, finance, and social sciences.
Typology
Main Sources
- Research: Open Research Data (ORD) / Open Scientific Data
- Government: Open Government Data (OGD)
- Non-profit Organisations
- Private Organisations
Disciplines
- Cultural Heritage
- Healthcare
- Education
- Transportation
- Meteorology
- Geospatial Information
- Economic and Finance
- Legal and Criminal Justice
- Etc.
Open Research Data (ORD)
Definition
Research data are the evidence that underpins the answer to the research question, and can be used to validate findings regardless of its form (e.g. print, digital, or physical). These might be quantitative information or qualitative statements collected by researchers in the course of their work by experimentation, observation, modeling, interview, or other methods, or information derived from existing evidence Concordat Working Group (2016).
For Funding Agencies (and Institutions)
- For the purposes of research assessment, consider the value and impact of all research outputs (including datasets and software) in addition to research publications, and consider a broad range of impact measures including qualitative indicators of research impact, such as influence on policy and practice.
For Organizations that Supply Metrics
- Be open and transparent by providing data and methods used to calculate all metrics.
- Provide the data under a licence that allows unrestricted reuse, and provide computational access to data, where possible.
ORD in Switzerland
SNSF Policy
The Swiss National Science Foundation (SNSF) expects all its funded researchers:
- to store the research data they have worked on and produced during the course of their research work,
- to share these data with other researchers, unless they are bound by legal, ethical, copyright, confidentiality or other clauses, and
- to deposit their data and metadata onto existing public repositories in formats that anyone can find, access and reuse without restriction.
https://www.snf.ch/en/dMILj9t4LNk8NwyR/topic/open-research-data
Vision
By facilitating access to and reuse of research data, ORD promotes better, more effective, and more impactful research for the benefit of society as a whole. Through the principles of open access and reusability of research data, ORD practices support transparent and reproducible research findings. Moreover, ORD fosters collaboration by promoting exchange among researchers across disciplines, legal systems and national borders, thus enabling creativity and innovation to thrive (Open Science Delegation, 2021a).
Action Areas
The SNSF has identified four criteria in the action plan (Open Science Delegation, 2021b):
- Support researchers and research communities in imagining and adopting ORD practices
- Development, promotion, and maintenance of financially sustainable basic infrastructures and services for all researchers
- Equipping researchers for ORD skills development and exchange of best practices
- Building up systemic und supportive conditions for institutions and research communities
→ for more information, see Wiel et al. (2024)
Research Data Management (RDM)
Definition
RDM refers to the organisation, storage and preservation of data created during a research project.
Purpose
RDM ensures that research data are well-organised, maintained and accessible for current and future research, thereby improving their reliability, validity and reproducibility.
Data Management Plan (DMP)
Definition
A DMP is a formal document that outlines how data will be handled during and after a research project, covering aspects from collection to sharing and preservation.
Purpose
It serves as a guide for managing data efficiently and meets funding agency requirements for data stewardship. It is now mandatory for most funding agencies to require a DMP as part of the grant application process to secure funding. University libraries often have services and resources to assist researchers in creating these documents, providing expert guidance on best practices in data management.
RDM and DMP
Interconnected Roles
RDM encompasses the day-to-day management of research data, while a DMP provides a structured plan for how to manage, share, and preserve data throughout the research project.
Planning and Execution
A DMP is essentially a blueprint for RDM. It outlines the policies and standards to be applied to the data, ensuring that data management practices are thought through from the outset of the project.
Open Governement Data (OGD)
Definition
The work of government involves collecting huge amounts of data, much of which is not confidential (economic data, demographic data, spending data, crime data, transport data, etc). The value of much of this data can be greatly enhanced by releasing it as open data, freeing it for re-use by business, research, civil society, data journalists, etc Open Knowledge (2016).
https://opendatahandbook.org/glossary/en/terms/government-data/
OGD in Switzerland
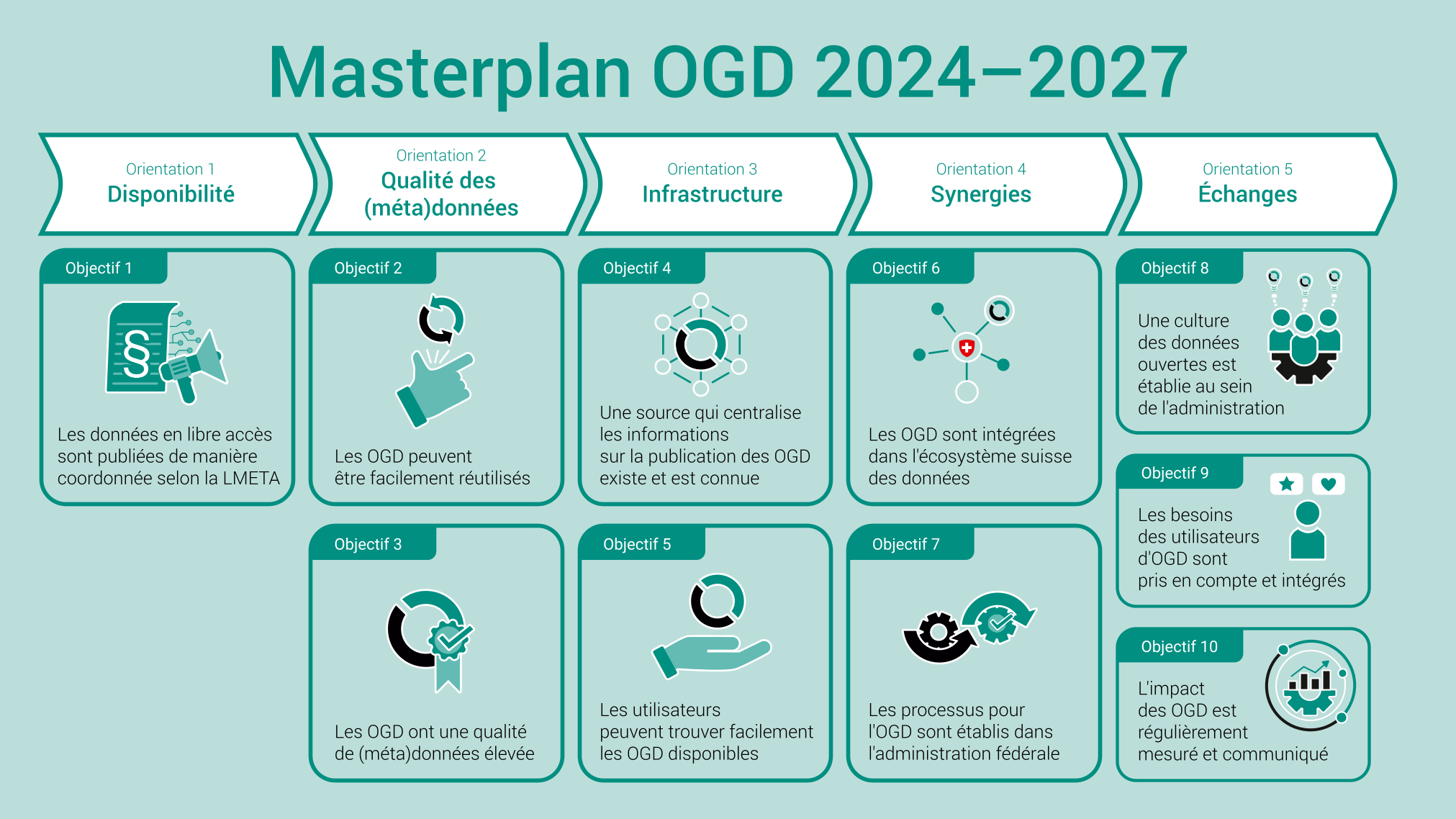
https://www.bfs.admin.ch/bfs/fr/home/services/ogd/masterplan.html
LMETA. Art. 10, al. 4
Les données sont mises en ligne gratuitement, en temps utile, sous une forme lisible par machine et dans un format ouvert. Elles peuvent être librement réutilisées, sous réserve d’obligations légales spéciales de mentionner la source des données (Loi fédérale sur l’utilisation des moyens électroniques pour l’exécution des tâches des autorités (LMETA), 2023).
Purposes of Open Data
- Transparency and democratic control
- Participation
- Self-empowerment
- Improved or new private products and services
- Innovation
- Improved efficiency and effectiveness of government services
- Impact measurement of policies
- New knowledge from combined data sources and patterns in large data volumes
https://opendatahandbook.org/guide/en/why-open-data/
Open Government Data Principles
- Complete: All public data is made available. Public data is data that is not subject to valid privacy, security or privilege limitations.
- Primary: Data is as collected at the source, with the highest possible level of granularity, not in aggregate or modified forms.
- Timely: Data is made available as quickly as necessary to preserve the value of the data.
- Accessible: Data is available to the widest range of users for the widest range of purposes.
- Machine processable: Data is reasonably structured to allow automated processing.
- Non-discriminatory: Data is available to anyone, with no requirement of registration.
- Non-proprietary: Data is available in a format over which no entity has exclusive control.
- License-free: Data is not subject to any copyright, patent, trademark or trade secret regulation. Reasonable privacy, security and privilege restrictions may be allowed.
Requirements
- Legally open: available under an open (data) licence that permits anyone freely to access, reuse and redistribute
- Technically open: data is available for no more than the cost of reproduction and in machine-readable and bulk form.
Licences
Copyright and Copyleft
Copyright
- Grants creators exclusive rights to control use, reproduction, and distribution.
- Designed to protect creators’ economic interests; allows monetization of work.
Copyleft
- Allows use, modification, and distribution with the condition of keeping works and derivatives open.
- Promotes freedom, sharing of knowledge, and collaborative improvement.
For further information about licences → Competence Center in Digital Law: https://www.ccdigitallaw.ch/
Creative Commons (CC)
 CC BY 4.0: Attribution
CC BY 4.0: Attribution CC BY-SA 4.0: Attribution, Share Alike
CC BY-SA 4.0: Attribution, Share Alike CC BY-ND 4.0: Attribution, No Deritave Works
CC BY-ND 4.0: Attribution, No Deritave Works CC BY-NC 4.0: Attribution, No Commercial Use
CC BY-NC 4.0: Attribution, No Commercial Use CC BY-NC-SA 4.0: Attribution, No Commercial Use, Share Alike
CC BY-NC-SA 4.0: Attribution, No Commercial Use, Share Alike CC BY-NC-ND 4.0: Attribution, No Commercial Use, No Derivative Works
CC BY-NC-ND 4.0: Attribution, No Commercial Use, No Derivative Works Public Domain Dedication (CC0): No Rights Reserved
Public Domain Dedication (CC0): No Rights Reserved Public Domain Mark: No Known Copyright
Public Domain Mark: No Known Copyright
Spectrum

Creative commons license spectrum (MJL, 2020)
Rights Statements
- 12 different rights statements that can be used by cultural heritage institutions
- Three categories
- In Copyright: statements for works that are in copyright
- No Copyright: statements for works that are not in copyright
- Other: statements for works where the copyright status is unclear
Open Data Commons Open Database License (ODbL)
- Copyleft licence
- Attribution and Share-Alike for Data/Databases
https://opendatacommons.org/licenses/odbl/
ODbL is somewhat equivalent to CC BY-SA (Santos, 2020).
Public Domain Dedication and License (PDDL)
- The PDDL places the data(base) in the public domain (waiving all rights)
Licences for software
- GNU General Public License (GPL)
- GNU Affero General Public License (AGPL)
- Mozilla Public License (MPL)
- MIT License
- Apache License
And others… → see for instance https://docs.github.com/en/repositories/managing-your-repositorys-settings-and-features/customizing-your-repository/licensing-a-repository
Responsable AI Licenses (RAIL)
Responsible AI Licenses (RAIL) are a class of licenses designed to encourage the responsible use of an AI artifact being licensed by including a set of use restrictions applied to AI artifact. RAILs can be more or less restrictive depending on the aims of the licensor. For instance, a license can be RAIL while being a proprietary license, or a license just allowing the use of the AI feature for research purposes and without allowing distribution of derivative versions.
In contrast, Open & Responsible AI Licenses (OpenRAIL) are a subclass of RAIL licenses that permit free-of-charge open access and re-use of AI artifacts for commercial purposes, while including usage restrictions. Note that usage restrictions in RAIL Licenses also apply to any derivatives of AI artifact.
RAILs can be used to license data (D), Apps (A), models (M), and source code (S). depending on the AI feature(s) you are licensing, you will add suffix D, A, M, or S
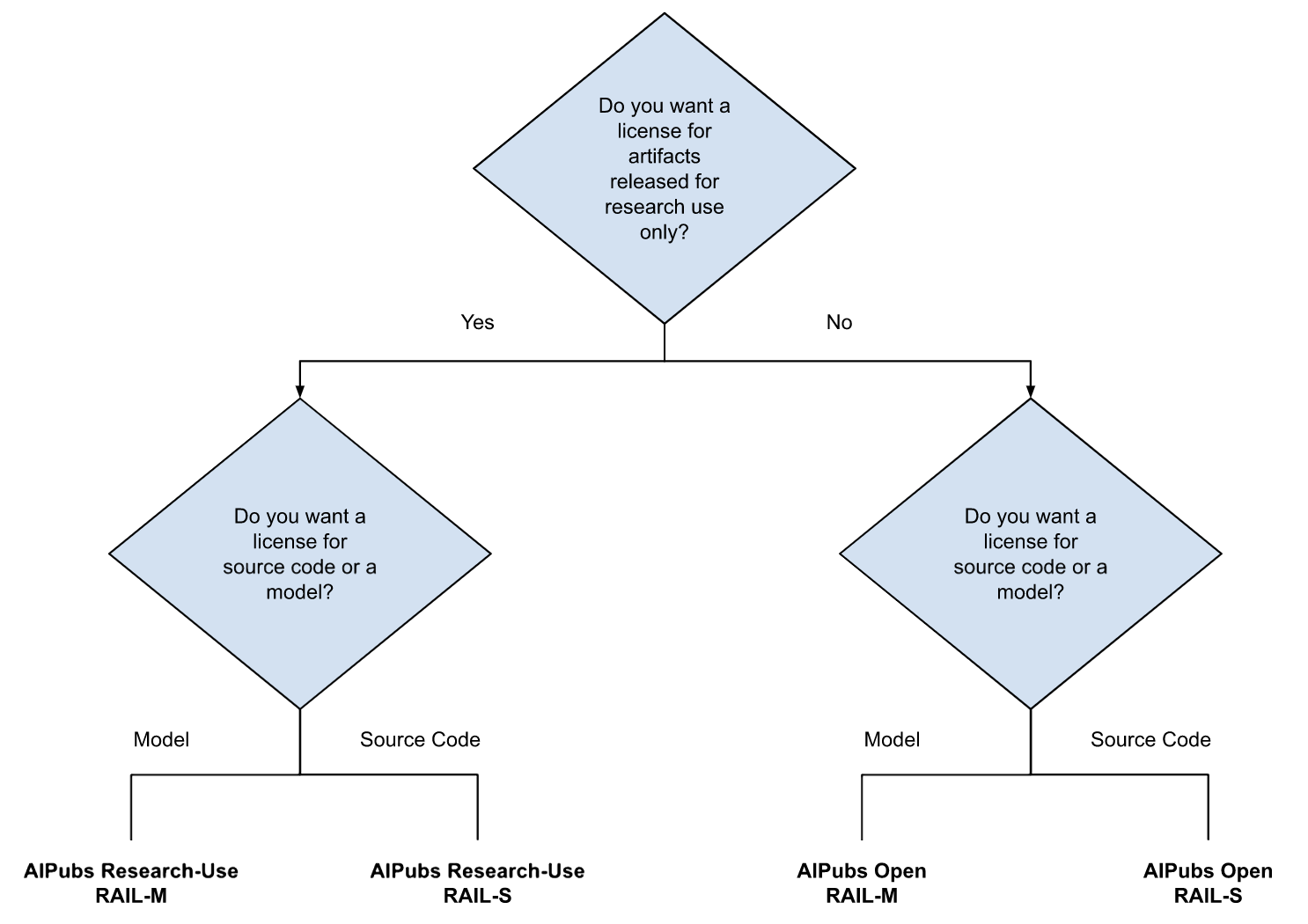
- Responsible AI Pubs Licenses
- AIPubs Open RAIL-S
- AIPubs Open RAIL-M
- AIPubs Research-Use RAIL-S
- AIPubs Research-Use RAIL-M
- Responsible AI End-User License (RAIL-A License)
- Responsible AI Source Code License (Open RAIL-S License)
- BigScience Open RAIL-M License (Open RAIL-M License)
I Hate AI License (IHAIL)
- Based on CC BY 4.0
- It prohibits the use of the material with Artifical Intelligence (AI) technologies while allowing sharing, adaptation, and commercial use under certain terms.
Recommendations for Open (Research) Data
Santos (2020) suggests assigning Creative Commons licenses to open datasets in the following order of preference:
- CC0 (to the fullest extent allowed by law, as a complete waiver is not feasible under Swiss regulations)
- CC BY 4.0
- CC BY-SA 4.0

Technical means
Important factors in providing structured data for machines
- Data(set) formats
- Text-based formats
- Binary-encoded formats
- Metadata standards / schemas (to describe the dataset)
- Documentation
- Protocols
And of course the underlying infrastructure…
Infrastructure
Definitions
A collective term for the subordinate parts of an undertaking; substructure, foundation (Oxford English Dictionary, 2023a).
People commonly envision infrastructure as a system of substrates – railroad, lines, pipes and plumbing, electrical power plants, and wires. It is by definition invisible, part of the background for other kinds of work. It is ready-to-hand. This image holds up well enough for many purposes – turn on the faucet for a drink of water and you use a vast infrastructure of plumbing and water regulation without usually thinking much about it (Star, 1999).
Dimensions
According to Star (1999), infrastructure can be understood through nine interconnected dimensions:
- Embeddedness: Infrastructure is sunk into and inside of other structures, social arrangements, and technologies. People do not necessarily distinguish the several coordinated aspects of infrastructure.
- Transparency: Infrastructure is transparent to use, in the sense that it does not have to be reinvented each time or assembled for each task, but invisibly supports those tasks.
- Reach or scope: This may be either spatial or temporal – infrastructure has reach beyond a single event or one-site practice.
- Learned as part of membership: Strangers and outsiders encounter infrastructure as a target object to be learned about. New participants acquire a naturalised familiarity with its objects, as they become members.
- Links with conventions of practice: Infrastructure both shapes and is shaped by the conventions of a community of practice.
- Embodiment of standards: Modified by scope and often by conflicting conventions, infrastructure takes on transparency by plugging into other infrastructures and tools in a standardised fashion.
- Built on an installed base: Infrastructure does not grow de novo; it wrestles with the inertia of the installed base and inherits strengths and limitations from that base.
- Becomes visible upon breakdown: The normally invisible quality of working infrastructure becomes visible when it breaks: the server is down, the bridge washes out, there is a power blackout.
- Is fixed in modular increments, not all at once or globally: Because infrastructure is big, layered, and complex, and because it means different things locally, it is never changed from above. Changes take time and negotiations, and adjustment with other aspects of the systems are involved.
Text-based formats
Plain Text (TXT)
WSe2 WS2 MoS2
dk Intensity dk Intensity dk Intensity
855.87628 63 848.96433 -39 855.87628 372
855.25787 72.25 848.34546 2 855.25787 424
854.63942 64.25 847.72654 -39 854.63942 460
854.02093 58 847.10759 -37 854.02093 362
853.40239 66 846.4886 -28 853.40239 440Sohier, T., Ponomarev, E., Gibertini, M., Berger, H., Marzari, N., Ubrig, N., & Morpurgo, A. F. (2019). Enhanced Electron-Phonon Interaction in Multivalley Materials [Data set]. Université de Genève, Yareta. https://doi.org/10.26037/yareta:jlzyhiwj6vfjrnbza4bkvobjai
File (extract): f1b.txt
Markdown (MD)
# e-periodica OAI-PMH - Ethnology and Folklore
This script was done to download the metadata of [e-periodica](https://www.e-periodica.ch/) through
their OAI-PMH endpoint (`https://www.e-periodica.ch/oai`) that could be interesting to the PIA research
project as we want to link our image-based collections to the e-periodica articles.
There are more than 16k metadata articles which have
the 390 `setSpec` (Ethnology, folklore) on e-periodica. Probably, the more relevant articles
come from the `Korrespondenzblättern der SGV` (more than 2k articles), divided into these three sources:
- https://www.e-periodica.ch/digbib/volumes?UID=sgv-001
- https://www.e-periodica.ch/digbib/volumes?UID=sgv-002
- https://www.e-periodica.ch/digbib/volumes?UID=sgv-003
## Records in CSV
- [All records](data/records.csv)
- [Extract (SGV)](data/sgv.csv)Raemy, J. A. (2023). e-periodica OAI-PMH - Ethnology and Folklore (Version 1.0.0) [Computer software]. https://doi.org/10.5281/zenodo.7777797 File: README.MD
Comma-separated values (CSV)
"TRANSPORT_TYPE";"TRANSPORT_MEAN";"TRAVEL_REASON";"SOCIO_DEMO_VARIABLE_TYPE";"SOCIO_DEMO_VARIABLE";"PERIOD_REF";"UNIT_MEAS";"VALUE";"OBS_CONFIDENCE";"OBS_STATUS"
"TOT";"TOT";"ALL_REAS";"GEO";"CH";2015;"KM";36.8318;0.4602;"A"
"TOT";"TOT";"WORK";"GEO";"CH";2015;"KM";8.8512;0.1995;"A"
"TOT";"TOT";"SCHOOL";"GEO";"CH";2015;"KM";1.9104;0.1026;"A"
"TOT";"TOT";"SHOP";"GEO";"CH";2015;"KM";4.7651;0.1346;"A"
"TOT";"TOT";"LEISU";"GEO";"CH";2015;"KM";16.2548;0.3385;"A"
"TOT";"TOT";"SERV_ACC";"GEO";"CH";2015;"KM";1.8462;0.0982;"A"
"TOT";"TOT";"BUSIN";"GEO";"CH";2015;"KM";2.5514;0.1587;"A"
"TOT";"TOT";"OTH_REAS";"GEO";"CH";2015;"KM";0.6527;0.0759;"A"
"SOFT_MOB";"TOT";"ALL_REAS";"GEO";"CH";2015;"KM";2.8031;0.0440;"A"Federal Statistical Office. Comportement de la population en matière de transports, tableaux de synthèse. https://opendata.swiss/fr/perma/18084205@bundesamt-fur-statistik-bfs
Extensible Markup Language (XML)
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dcat="http://www.w3.org/ns/dcat#"
xmlns:dct="http://purl.org/dc/terms/"
xmlns:vcard="http://www.w3.org/2006/vcard/ns#">
<dcat:Dataset rdf:about="https://ckan.opendata.swiss/perma/121911@bundesamt-fur-statistik-bfs">
<dcat:keyword xml:lang="it">lavoro-e-reddito</dcat:keyword>
<dct:language>fr</dct:language>
<dcat:distribution>
<dcat:Distribution rdf:about="https://ckan.opendata.swiss/dataset/90beaddf-4f48-4211-9e34-ff68d4308f98/resource/f9eb3fb4-0a11-4a40-a995-0aa13f377011">
<dct:rights rdf:resource="http://dcat-ap.ch/vocabulary/licenses/terms_by_ask"/>
<dcat:downloadURL rdf:resource="https://dam-api.bfs.admin.ch/hub/api/dam/assets/121910/master"/>
<dcat:accessURL rdf:resource="https://dam-api.bfs.admin.ch/hub/api/dam/assets/121910/master"/>
<dct:format rdf:resource="http://publications.europa.eu/resource/authority/file-type/XLS"/>
<dct:title xml:lang="de">Kanton Genf: Erwerbsleben und Ausbildung</dct:title>
<dct:identifier>121910-master@bundesamt-fur-statistik-bfs</dct:identifier>
<dct:language>de</dct:language>
<dcat:mediaType rdf:resource="http://www.iana.org/assignments/application/vnd.ms-excel"/>
<dct:description xml:lang="de">Dieser Dataset präsentiert die Zahlen zu Erwerbsleben und Ausbildung (Eidgenössische Volkszählung 2000)</dct:description>
<dct:license rdf:resource="http://dcat-ap.ch/vocabulary/licenses/terms_by_ask"/>
</dcat:Distribution>Federal Statistical Office. Canton de Genève: Vie active et formation https://opendata.swiss/fr/perma/121911@bundesamt-fur-statistik-bfs
Terse RDF Triple Language (Turtle)
@prefix ns1: <https://data.tg.ch/ld/ontologies/div-energie-6/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<https://data.tg.ch/ld/resources/div-energie-6/div-energie-6-record/1740b190a1beca6edcd04e0b143c380b885ee1de/>
a ns1:div-energie-6-record ;
ns1:andere "2690"^^xsd:int ;
ns1:einwohner "266510"^^xsd:int ;
ns1:energiebezugsflaeche "25055573"^^xsd:int ;
ns1:erdgas "308728"^^xsd:int ;
ns1:erdoelbrennstoffe "307734"^^xsd:int ;
ns1:jahr "2015-01-01"^^xsd:date ;
ns1:kehricht "78654"^^xsd:int ;
ns1:total "1291573"^^xsd:int ;
ns1:treibstoffe "593764"^^xsd:int .Kanton Thurgau. CO2-Gesamtemissionen nach Energieträgern (Ebene Kanton) - https://opendata.swiss/de/perma/div-energie-6@kanton-thurgau - https://data.tg.ch/ld/resources/div-energie-6/div-energie-6-record/1740b190a1beca6edcd04e0b143c380b885ee1de/
JavaScript Object Notation (JSON)
EPFL. Citations extracted from monographs about the history of Venice. https://opendata.swiss/de/perma/EPFL-LinkedBooksMonographs@openglam
JavaScript Object Notation for Linked Data (JSON-LD)
{
"id": "https://lux.collections.yale.edu/data/group/8b757ad2-f853-425e-a30d-19686aa779ee",
"type": "Group",
"_label": "American Academy of Arts and Sciences",
"@context": "https://linked.art/ns/v1/linked-art.json",
"formed_by": {
"type": "Formation",
"timespan": {
"type": "TimeSpan",
"identified_by": [
{
"type": "Name",
"content": "1780-05-04",
"classified_as": [
{
"id": "https://lux.collections.yale.edu/data/concept/5088ec29-065b-4c66-b49e-e61d3c8f3717",
"type": "Type",
"_label": "Display Title",
"equivalent": [
{
"id": "http://vocab.getty.edu/aat/300404669",
"type": "Type",
"_label": "Display Title"
}
]
}
]
}
],
"end_of_the_end": "1780-05-04T23:59:59",
"begin_of_the_begin": "1780-05-04T00:00:00",
"_seconds_since_epoch_begin_of_the_begin": -5985100800,
"_seconds_since_epoch_end_of_the_end": -5985014401
},
"carried_out_by": [
{
"id": "https://lux.collections.yale.edu/data/person/977a4f7a-5d26-4965-8dd9-3fb0eaa4267e",
"type": "Person",
"_label": "John Adams"
},
{
"id": "https://lux.collections.yale.edu/data/person/73e7af34-fe41-4771-93df-e74b073d82fb",
"type": "Person",
"_label": "James Bowdoin"
}
]
},
(...)LUX (Yale University). American Academy of Arts and Sciences. https://lux.collections.yale.edu/data/group/8b757ad2-f853-425e-a30d-19686aa779ee
Binary-encoded Formats
Binary files are used to store non-text data, such as images, audio, or executable programs. These files do not contain human-readable text and are encoded in binary format.
- Image Formats: BMP, GIF, JPEG, JPEG2000, PNG, TIFF
- Vector Graphics Formats: EPS, PSD, SVG
- 3D Formats: 3MF, GLB, GLTF, OBJ, STL
- Audio Formats: AAC, FLAC, MP3, OGG, WAV
- Video Formats: AVI, FFV1/MKV, MOV, MP4, WEBM
- Documents: DOCX, ODT, PDF, PDF/A
- Scientific Data Formats: CDF, DICOM, FITS
- Archive File Formats: 7-ZIP, GZIP, TAR, ZIP

1706-11-30_Verzaglia_Giuseppe-Bernoulli_Johann_I. https://iiif.dasch.swiss/0801/4VjgCwiTn8p-CTaooIqSZBO.jpx/full/max/0/default.jpg
{kind=link}
Metadata standards / schemas
- Metadata standards are sets of rules and guidelines that dictate how metadata should be formatted and used. They ensure consistency and interoperability across different systems and platforms.
- CIDOC Conceptual Reference Model (CIDOC-CRM), Dublin Core, Machine-Readable Cataloging (MARC), Preservation Metadata: Implementation Strategies (PREMIS)
- Metadata schemas are specific implementations of metadata standards. They outline the structure, elements, and attributes of metadata for a specific purpose.
- Encoded Archival Description (EAD), Lightweight Information Describing Object (LIDO), Metadata Object Description Schema (MODS)
Data Catalog Vocabulary (Application Profiles)
- Resource Description Framework (RDF) vocabulary to facilitate interoperability between data catalogues published on the Web.
- Current version: DCAT 3
Data Catalog Vocabulary Application Profile (DCAT-AP)
Specifications based on DCAT for describing public sector datasets
- DCAT Application Profile for data portals in Europe: DCAT-AP 3.0
- DCAT Application Profile for the United States of America: DCAT-US - Version 3
- DCAT Application Profile for Data Portals in Switzerland (DCAT-AP CH): eCH-0200
DCAT-AP CH is a subprofile of DCAT-AP
DCAT
Seven main classes/entities:
dcat:Catalogrepresents a catalogue, which is a dataset in which each individual item is a metadata record describing some resourcedcat:Resourcerepresents a dataset, a data service or any other resource that may be described by a metadata record in a catalogue.dcat:Datasetrepresents a collection of data, published or curated by a single agent or identifiable community.dcat:Distributionrepresents an accessible form of a dataset such as a downloadable file.dcat:DataServicerepresents a collection of operations accessible through an interface (API) that provide access to one or more datasets or data processing functions.dcat:DatasetSeriesis a dataset that represents a collection of datasets that are published separately, but share some characteristics that group them.dcat:CatalogRecordrepresents a metadata record in the catalogue, primarily concerning the registration information, such as who added the record and when.

https://www.w3.org/TR/vocab-dcat-3/#dcat-scope
ex:catalog
a dcat:Catalog ;
dcterms:title "Imaginary Catalog"@en ;
dcterms:title "Catálogo imaginario"@es ;
rdfs:label "Imaginary Catalog"@en ;
rdfs:label "Catálogo imaginario"@es ;
foaf:homepage <http://dcat.example.org/catalog> ;
dcterms:publisher ex:transparency-office ;
dcterms:language <http://id.loc.gov/vocabulary/iso639-1/en> ;
dcat:dataset ex:dataset-001 , ex:dataset-002 , ex:dataset-003 ;
.DCAT-AP CH
@prefix dcat: <http://www.w3.org/ns/dcat#> .
@prefix dct: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
# ---------- class Catalog --------------------------------------------------
<https://swisstopo/opendata/catalog>
a dcat:Catalog ;
# mandatory properties
dct:description "Datenkatalog der Stadt Zurich"@de ;
dct:publisher <https://publishers/swisstopo> ;
dct:title "Open Data City of Zurich"@en ,
"Offene Daten der Stadt Zurich"@de .https://www.dcat-ap.ch/releases/2.0/dcat-ap-ch.html#Class:Catalog
Documentation
Comprehensive and understandable information about the data, including its source, structure, context, and how to use it effectively.
Types of Documentation
Clear and comprehensive documentation plays a vital role in maximizing the value of data and systems. It enhances usability by making data more accessible and understandable to a wide range of users, including non-experts and developers. Well-documented data fosters trust by providing transparency about sources, methodologies, and underlying code, while also supporting data integration and application development by enabling seamless combination of data from diverse sources. Below are key types of documentation that contribute to these goals:
- Data field descriptions/data models
- User guides
- Metadata
- Developer documentation
- Source code documentation
Protocols
A robust set of rules and standards governs the exchange and accessibility of open data over the internet. These protocols and mechanisms enable accessibility by facilitating standardised and straightforward access to data, which is essential for promoting innovation and transparency. Additionally, they support interoperability, ensuring that data from diverse sources can be efficiently integrated and used together. Below are key technologies and protocols that achieve these goals:
- Application Programming Interface (API): mechanism that enable two software components to communicate with each other
- Representational State Transfer (REST): a style of API that uses HTTP requests for communication. REST is stateless, i.e. each request from a client to the server is treated as new. There is no stored memory of previous interactions. This means the server does not store any state about the client session on the server side.
- Simple Object Access Protocol (SOAP): a protocol used for exchanging structured information in web services, offering high security and transactional reliability. SOAP can support both stateless and stateful operations.
- File Transfer Protocol (FTP): used for the transfer of data files, particularly large datasets, from one host to another.
- Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH): a protocol for harvesting metadata descriptions of records in an archive, particularly used in digital libraries.
- Really Simple Syndication or Rich Site Summary (RSS) / Atom Feeds: used for regularly updating or publishing data that changes frequently. Feeds enable publishers to syndicate data automatically.
- SPARQL Protocol and RDF Query Language (SPARQL): used for querying and manipulating RDF
Condensed Slide Version
Use arrow keys or the controls at the bottom to navigate through the presentation. Press f for fullscreen mode.
{kind=link}